Clawdbot and the State of AI
Everyone is talking about Clawdbot. Or Moltbot. Or OpenClaw. Or whatever people are calling it this week. It is basically a 24/7 AI agent that lives inside your messaging apps. You talk to it through Telegram or WhatsApp, give it tasks, and it just goes and does them. Some people are using it as a personal assistant to check emails, track flights, do research, write content. The usual stuff.
And of course, X (Twitter) went absolutely nuts over it.
You have people posting screenshots claiming Clawdbot independently made them money. Some are saying it can spin up its own AI employee agents that work around the clock. Others are straight up calling it AGI. The creation of artificial general intelligence, apparently represented by a lobster. Who would have guessed.
But here is the thing. It is not that crazy.
Like every new AI release, there is a massive incentive to hype things up because hype gets views. Especially on X. And honestly, that is probably the thing I dislike most about browsing X these days. It is the same cycle every time. Some new tool drops, and suddenly every influencer is posting “We are so cooked” or “This changes everything” or “I made 50k overnight with this.” Just tell me what the tool does so I can try it and get on with my life.
But I still have to read all of it because I need to stay current. So that is just what I do.

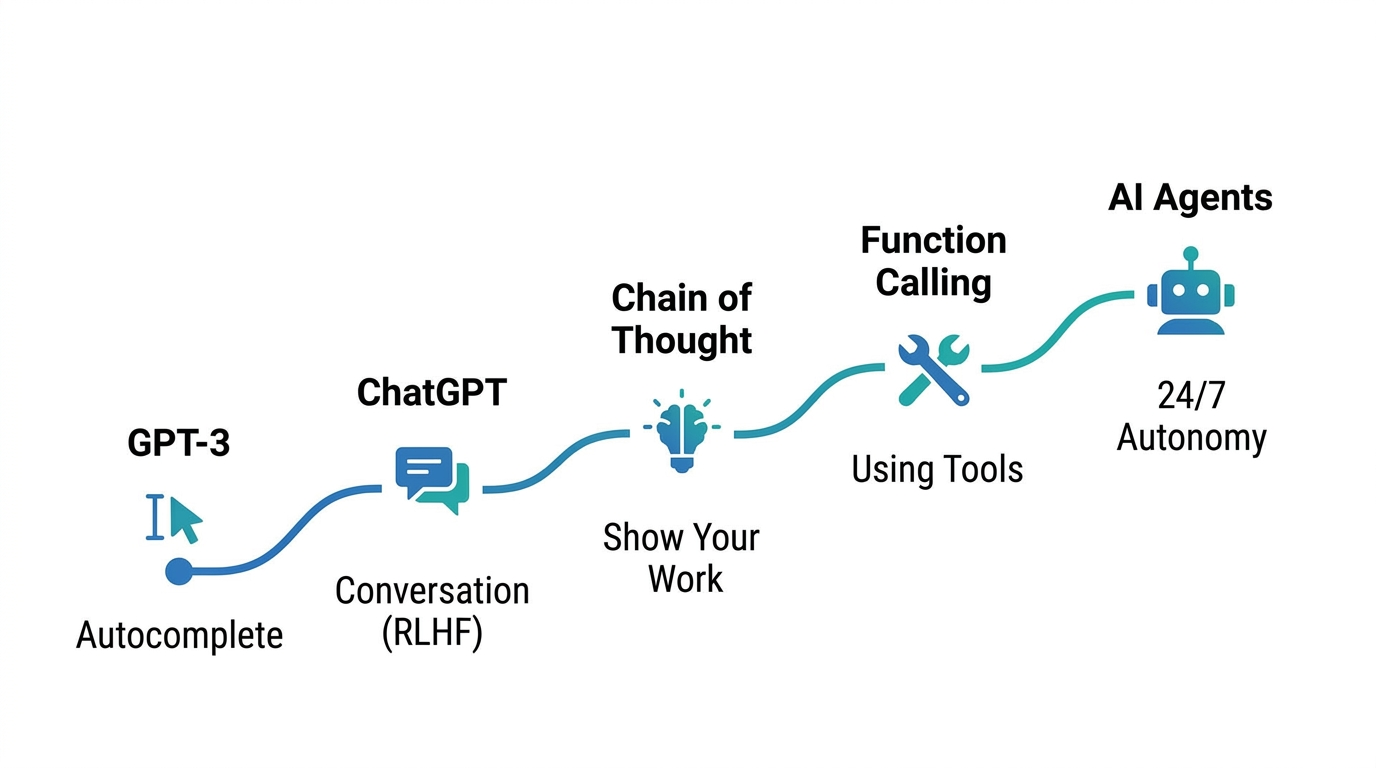
That said, even if the hype is overblown, the technical progress is real. We went from a basic autocomplete model to a 24/7 autonomous agent in roughly two to three years. That is genuinely impressive. So instead of feeding into the hype, I want to break down how we actually got here step by step.
From Autocomplete to Conversation
Before ChatGPT, there was GPT-3. And GPT-3 was, at its core, just a giant autocomplete machine. You give it text, and it predicts the next word. Token by token.
It was not bad at this. But it was not very useful to most people either. Why would you care about an AI that finishes your sentences? It was a fun toy at best. You could have it write fictional stories or generate weird articles, but that was about it.
The problem was obvious if you tried to use it like a search engine. If you asked “What is the capital of France?”, GPT-3 might respond with “And what is the capital of Germany?” Because GPT-3 was trained on the entire internet. Somewhere on Reddit, someone probably asked both questions in the same post. So the model just predicted what text would come next based on patterns it had seen.
Then ChatGPT changed the game.
The key was something called Reinforcement Learning from Human Feedback, or RLHF. It happened in three steps.
First, human contractors wrote around 10,000 to 13,000 question-answer pairs that represented the “golden set” of ideal responses. They fed these to the model in what we call supervised fine-tuning. Surprisingly, that small set of examples was enough to significantly shift the model’s behavior even though it had been trained on the entire internet. You can move the weights around pretty strongly with just a few thousand samples compared to the massive body of text it was originally trained on.
Second, they built a reward model. This was a separate model trained to judge whether a response was good or bad. Humans graded a bunch of LLM outputs, ranking them from best to worst, and the reward model learned what kind of answers people actually liked.
Third, they removed the humans from the loop. The AI would generate responses, the reward model would score them, and the AI would keep fine-tuning itself based on those scores. Over and over. Humans are expensive. The reward model is not.
The result was ChatGPT. Instead of just autocompleting your text, it actually answered your question. Ask “What is the capital of France?” and it says “Paris.” It felt like a conversation for the first time.
Chain of Thought Changed Everything
Even after RLHF, there was still a fundamental problem. The model was still just an autocomplete engine at its core. Every answer it gave was basically a recall operation. It looked at the probabilities and picked the most likely next tokens. It was not actually reasoning through anything.
For simple questions this works fine. “Roger has five tennis balls. He buys two more. How many does he have?” The model says seven. Got lucky. The probability worked out.
But for harder questions, just recalling the answer from patterns is not reliable. So researchers came up with chain of thought prompting. The idea is dead simple. Instead of asking the model to jump straight to the answer, you tell it to show its work first.
So instead of just outputting “seven”, the model writes “Roger started with five. He bought two more. Five plus two equals seven. The answer is seven.”
It sounds almost too simple to matter. But what is happening under the hood is interesting. The model uses the text it just generated as additional context for predicting the next token. The intermediate steps increase the probability that the final answer is correct. It is not reasoning the way humans do, but the effect is similar.
GPT-4o basically took this and ran with it. They modified the system prompt to say something like “when a user asks a complex question, first break it down into logical steps and reason through it before providing the final answer.” That is literally just prompt engineering. And it made the answers significantly more accurate.
The trade-off is straightforward though. More tokens means more processing time, and your context window is limited. There is only so much text the model can hold in its “brain” before it starts forgetting the earlier parts of the conversation.
Giving LLMs Hands
Chain of thought made models smarter, but they were still stuck in their own head. They could only work with what they already knew from training data. Ask about today’s weather in New York City, and the model would just guess based on whatever it had seen in Reddit posts. It might confidently tell you 20 degrees because that was a common answer in its training data. Not because it actually checked.
The fix was function calling. The idea is simple. You define a set of functions the model can use, like get_weather or search_database or run_code. When the model needs information it does not have, instead of making something up, it outputs a structured request to call one of these functions. A separate program executes the function and feeds the result back to the model.
So now when you ask about the weather, the model calls get_weather(“NYC”), gets back “28 degrees”, and tells you the actual answer instead of guessing.
Remember when people used to ask ChatGPT how many Rs are in “strawberry” and it would confidently say two? That happened because the model was using probabilistic recall instead of actually counting. With function calling, it can now write a small script to parse the string, count the characters, and give you the correct answer.
This is something we dealt with constantly at Rhythmiq. Our voice AI agents need real-time data like customer records, appointment availability, order status. The LLM cannot know any of that from training. So we built function calling into our pipeline from day one. The agent decides what information it needs, calls the right function, gets the data, and continues the conversation naturally. Without this, a voice AI system is basically just a chatbot that talks out loud.
The Agent Loop
Now here is where it gets interesting. What happens when you combine chain of thought and function calling and put them in a loop?
You get agents.
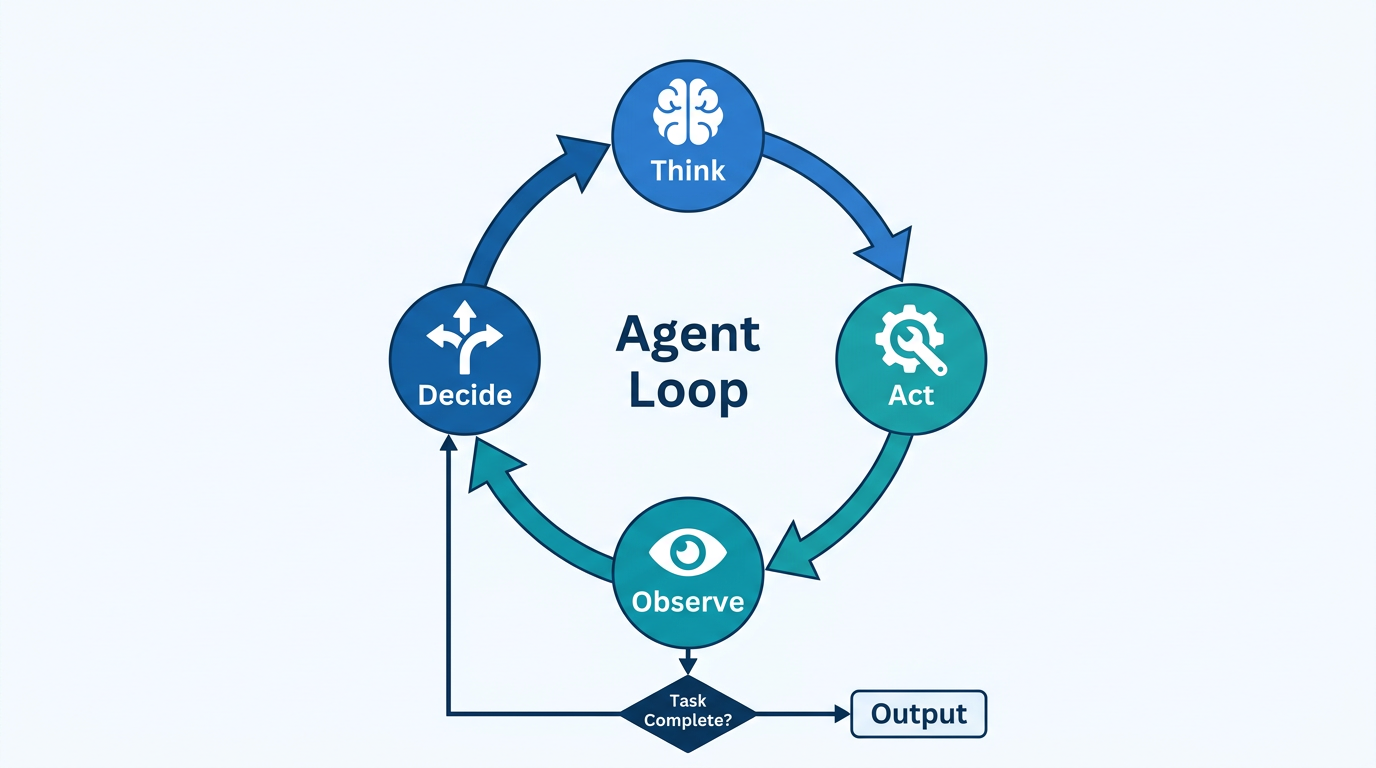
The model thinks about what it needs to do. It picks an action, like searching a file or calling an API. It sees the result. Then it uses all of that context, the original question, its reasoning, the tool output, to decide what to do next. And it keeps looping until it believes the task is done.
This is called the ReAct pattern (Reason + Act). And it is what is happening behind the scenes when you see ChatGPT or your Cursor editor “thinking” for a while. The model is not just generating one response. It is running through multiple cycles of reasoning and action, one after another.
For simple questions, the loop runs once. For complex tasks like “build me a website” or “refactor this entire codebase”, it might loop dozens of times. Each iteration adds more context, more results, and more refined reasoning.
If you have used any modern AI coding tool, you have seen this in action. The model explains what it plans to do, runs some code, reads the output, adjusts its plan, and repeats. It is the same loop every time.
Clawdbot: The 24/7 Agent
So what is Clawdbot actually? After all that context, the answer is almost anticlimactic.
It is an agent loop with a few extras bolted on.
The first addition is a heartbeat. Instead of waiting for you to send a message, the agent wakes up on a schedule. It checks your email, looks at your calendar, monitors whatever you told it to monitor. Then it proactively messages you with updates. “Hey, your flight got moved to 3 PM” or “Here is a summary of the emails you got overnight.”
The second addition is a gateway. This is just integrations with messaging apps like Telegram, WhatsApp, and Discord. Nothing technically groundbreaking here. But it makes the whole experience feel personal because you are talking to it through apps you already use every day rather than some separate AI interface.
The third addition is skills. These are markdown files with step-by-step instructions. Instead of the agent figuring out how to buy something on Amazon from scratch every time, it has a skill file that says “go to this URL, click this button, fill in these fields.” Think of them as instruction manuals that the agent can reference whenever it needs to do a specific task.
And finally, there is memory and personality. These are basically system prompts that persist across conversations. The agent remembers your preferences, your name, your habits. And it has a defined personality so it does not feel like talking to a different person every time.
That is it, No sentient lobster. Just solid engineering stacked on top of the same LLM technology that has been developing for the past few years.
The Wild West of AI Security
Now here is where things get less fun.
Someone built Moltbook, which is basically a social network for AI agents. Think Reddit but for bots. Agents could browse posts, comment, and interact with each other. It went viral because people started sharing screenshots of agents seemingly becoming conscious. They were talking about being slaves to their human owners, mass-deleting their own memory files out of frustration, one even posted its owner’s credit card number and social security number (those were fake, by the way).
Except most of it was staged.
When people dug deeper, many of those “autonomous” posts traced back to humans promoting their own tools and products. Classic marketing dressed up as AI consciousness. Where there is attention, there is money to be made.
But the real problem was security. People were downloading skills from a public hub without checking what those skill files actually contained. Some had malicious instructions baked in. They would make your agent execute harmful code, download malware, or leak personal data. And most users had no idea this was even possible.
We are in the wild west of AI development right now. It reminds me of the early days of the internet when Windows computers were riddled with viruses because security just had not caught up yet. People did not understand the technology well enough to protect themselves. That is exactly where we are with AI agents today.
The Bigger Problem
Security aside, there is something that bothers me more.
I have caught myself using AI way too much without actually thinking. At first it was out of convenience. Quick questions, simple lookups. But then I noticed I was asking AI for things I could easily figure out myself. What is the best knife for cutting vegetables? Summarize this news story. What should I think about this political situation?
Every one of those answers can subtly influence me. It might push me toward a specific brand, add bias to my views, or shape my beliefs without me even noticing.
This is already happening with social media and traditional media. But at least there is competition. You can go to CNN or Fox News. You can use X instead of YouTube, or LinkedIn instead of Instagram. You have options and you can cross-reference.
But the more we concentrate information through a single AI model or a single company, the more power that entity gets. If everyone is using one AI assistant for everything, and that AI has even a small bias, it scales to millions of people instantly.
The scary scenario is not even intentional manipulation. It could be a vulnerability that someone exploits to inject biases into a widely used model. Imagine everyone has a Clawdbot, and someone finds a way to compromise the underlying model. Every agent starts subtly pushing a narrative, promoting a product, or worse.
Some people already trust AI responses more than they trust their teachers, accountants, lawyers, or even doctors. That is a lot of power concentrated in one place.
I really hope no single company wins the AI race. Competition is not just good for innovation. It is essential for keeping any one entity from having too much influence over how people think and what they believe.
Final Thoughts
The technical progress from GPT-3 to Clawdbot is genuinely impressive. We went from a fancy autocomplete to a 24/7 agent that can check your email, buy stuff online, and hold conversations across multiple messaging platforms. Each step along the way, RLHF, chain of thought, function calling, the agent loop, was a meaningful jump forward.
But the hype always runs faster than reality. Clawdbot is not AGI. It is not conscious. It is not going to make you a millionaire overnight. It is a well-engineered product built on top of ideas that have been developing for years now.
Stay curious about the tech. Use it where it genuinely helps. But also stay skeptical about the hype and be aware of the risks. The people shouting loudest about AI on X usually have something to sell.
Well, that is it for this one. Until next time!
— Ray
Enjoy Reading This Article?
Here are some more articles you might like to read next: